In the first article we’ve learned how to create scalable and efficient implementation of JOIN operation. Our second problem will be focused on how to extract small subset of records from immensely large collection. This problem occurs often in big data processing.
I am going to use the same domain model that I used in previous example.
Once again, we are building an ads engine.
We have a huge pool of sessions, where each session corresponds to a sequence of events of a single
user during brief amount of time.
Let’s further suppose that every session has url field that carries webpage address of where these events occurred.
We also have a text file with some number of URLs and we would like to extract all sessions from our large
pool of sessions which have one of these URLs.
Important is that we expect that number of selected sessions will be negligibly small compared to the overall amount of sessions.
For example, we could have 10 TB of sessions, 100 MB text file with URLs and we expect to get 20 GB of sessions in the result.
There are myriad possible situations leading to this problem:
maybe we want to check some statistical hypothesis over the websites of specific thematics,
maybe one of our clients requested all associated information.
or maybe we just want to recompute KPIs.
In all cases, the statement of SELECT problem is the same:
how to extract small subset of data from immensely large collection by primary or secondary key.
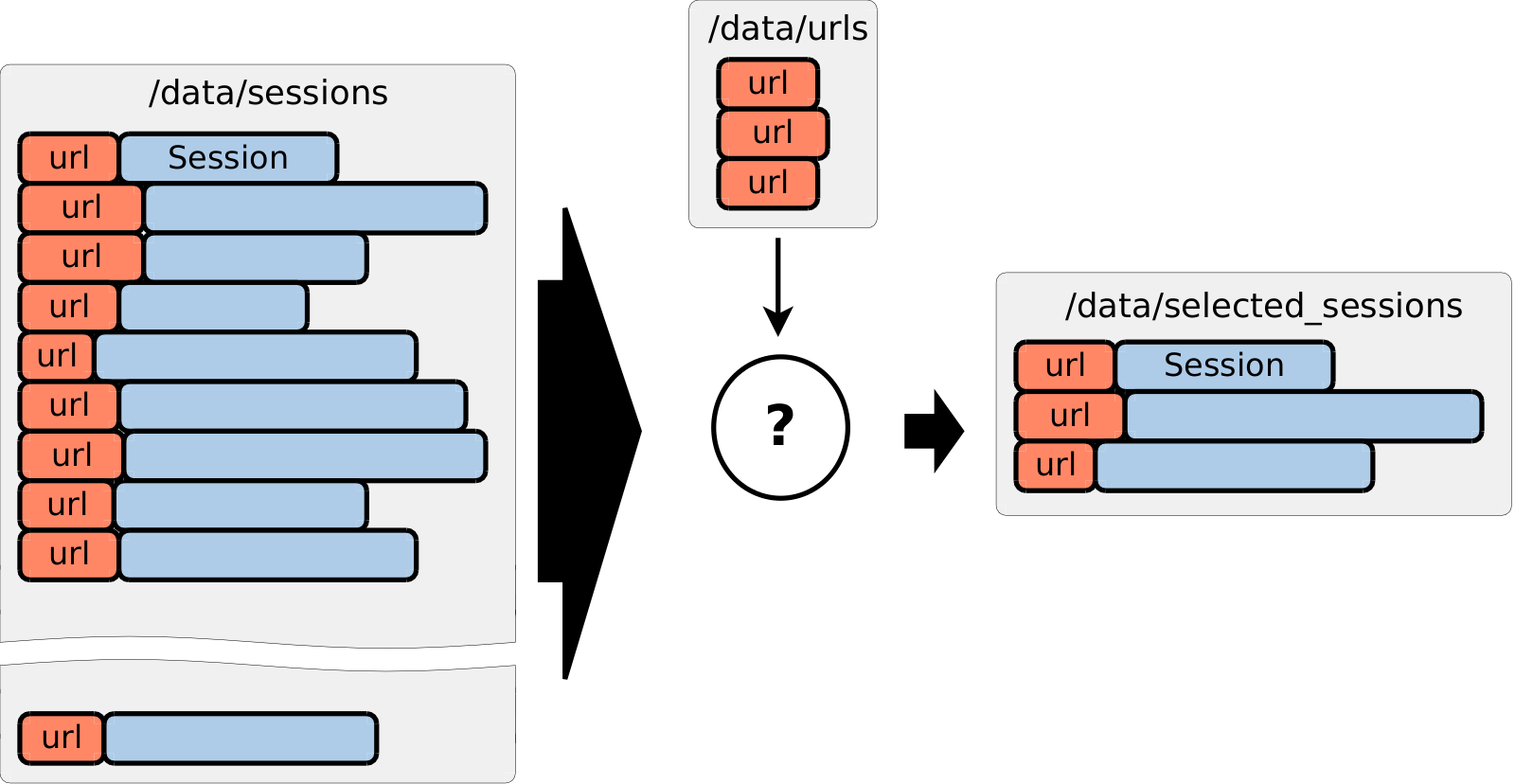
Because this is an ad hoc problem, we do not want to waste time on building index — we’d rather
stick with one full scan over the sessions collection.
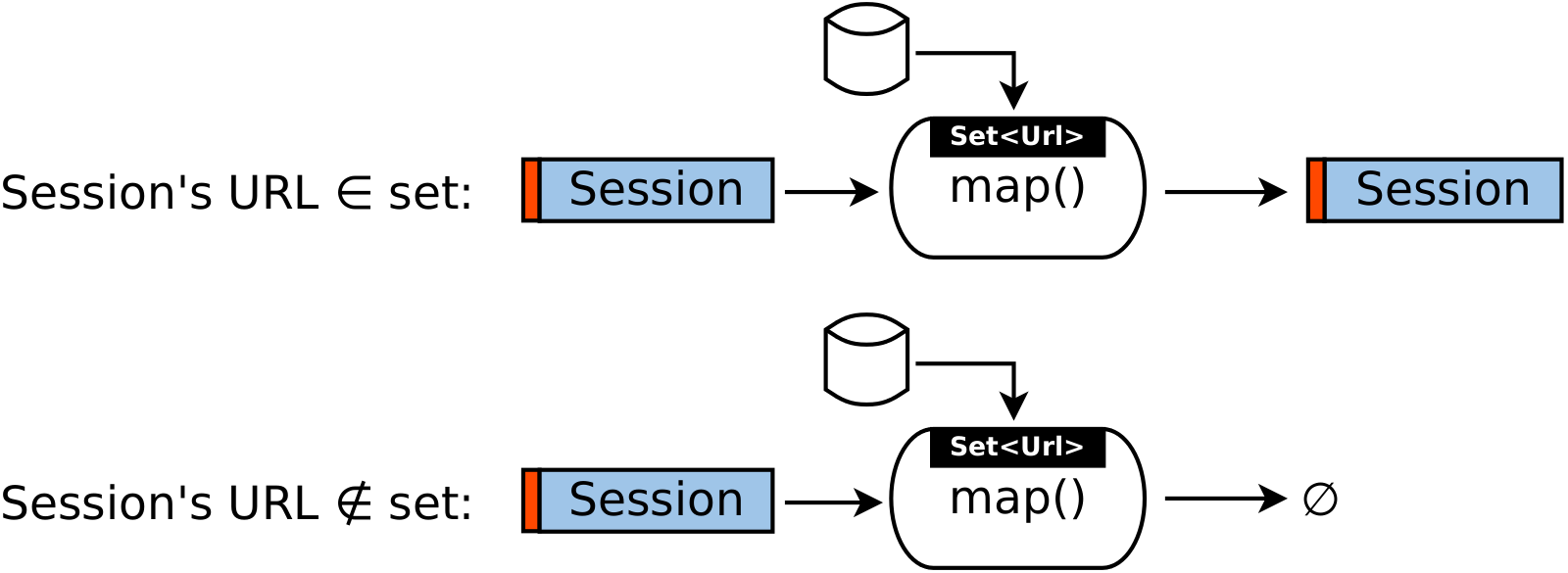
First indexless solution that comes to my mind is to avoid using reducers and do filtering directly in mappers.
Because number of URLs is small, we can load them into each mapper in the setup() method
and then use them to filter incoming sessions.
Sessions that pass our check go directly from mappers to output files.
We can still use reducers in order to control the number of output files.
Indeed, using mapper-only approach would create one output file per each split of input data (100 MB by default),
resulting in tens of thousands of tiny files, which may be inconvenient.
Code below demonstrates mapper-only approach.
We create sequence file of URLs in main code (not shown) in format (NullWritable, Any{url}) and pass its path to mappers
via conf.url.path configuration option.
Mappers load this file in setup() method.
Next, every incoming session is checked against this list.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24 private List<String> urls = new ArrayList<>(); // list of URLs of interest
protected void setup(Mapper<NullWritable, Any, IntWritable, Any>.Context context) {
Configuration conf = context.getConfiguration();
Path path = new Path(conf.get("conf.url.path"));
SequenceFile.Reader reader = new SequenceFile.Reader(conf, SequenceFile.Reader.file(path));
NullWritable key = NullWritable.get();
Any value = new Any();
while (reader.next(key, value)) {
urls.add(value.url);
}
reader.close();
Collections.sort(urls);
}
protected void map(NullWritable key, Any value,
Mapper<NullWritable, Any, NullWritable, Any>.Context context) {
if (value.session != null) {
if (Collections.binarySearch(urls, value.session.url) >= 0) {
context.write(NullWritable.get(), new Any(value.session));
}
}
}
Code above works well but only when all URLs fit into RAM. Once URL volume exceeds memory of a single mapper, this solution cannot be used anymore. You will have to split URL list into sublists and to run multiple jobs over the same input data but with different sublists. This is expensive.
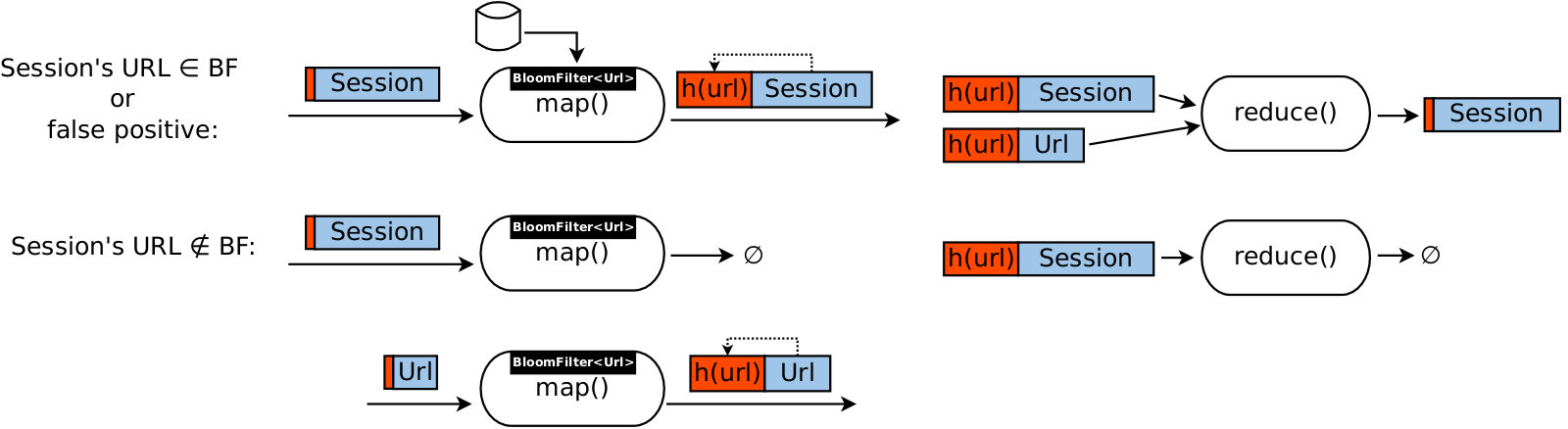
To make our job independent on number of URLs, we are going to use classical MapReduce approach.
As in first version, we will first create a sequence file with URLs in format (NullWritable, Any{url}) and put in HDFS.
Next we will create a job that tasks both URLs and sessions files as input and joins them.
URL is used as join key, so that all objects — both sessions and URLs — are delivered to the same reducer.
Reducer emits only those sessions which have URL from our list of interest.
To optimize sorting operation, hash(URL) is used as a key instead of URL itself.
This slightly complicates reducer because now there is a chance that multiple URLs will map into the same hash(url).
As such, reducer has to track multiple URLs at once.
We also assume that number of sessions with single URL is small.
In real-world, this might not be the case, and we would have to use the approach described in previous article.
That is, to split sessions with the same URLs into multiple shards with the key {hash(URL), shardId(0..20)}.

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28 protected void map(NullWritable key, Any value,
Mapper<NullWritable, Any, IntWritable, Any>.Context context) {
if (value.session != null) {
context.write(new IntWritable(value.session.url.hashCode()), new Any(value.session));
}
if (value.url != null) { // use hash(url) to increase sort performance
context.write(new IntWritable(value.url.hashCode()), new Any(value.url));
}
}
protected void reduce(IntWritable key, Iterable<Any> values,
Reducer<IntWritable, Any, NullWritable, Any>.Context context) {
Set<String> urls = new HashSet<>();
List<Session> sessions = new ArrayList<>();
for (Any value : values) {
if (value.url != null) {
urls.add(value.url);
}
if (value.session != null) {
sessions.add(value.session);
}
}
for (Session session : sessions) {
if (urls.contains(session.url)) {
context.write(NullWritable.get(), new Any(session));
}
}
}
Compared to the first version, the above code works for any number of input URLs. But the problem is that it is extremely inefficient. Indeed, it sorts and transfers the whole volume of sessions from mappers to reducers, even though we need tiny fraction of it. Situation when all reducers combined receive dozens of terabytes of sessions but emit only couple of gigabytes to the output is typical for the above solution.
Now we have two solutions: one is efficient but is not scalable, another one is scalable but is not efficient. In order to get benefits of both of them, we are going to combine them, replacing ordinary set of URLs in mapper with Bloom filter. This results in that now we have two filters: one is a rough filter on mapper, another one is a precise filter on reducer. First filter removes almost all irrelevant data not including small amount of false positives — sessions with URLs that were not added to Bloom filter but which are reported as if they were added. Reducer provides second filtering stage and removes final bits of irrelevant data from the stream. For example, consider typical situation when Bloom filter removes 97% of input sessions and reducer removes 2% more.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52 private BloomFilter urls = new BloomFilter(32*1024*1024*8, 50); // 32 MiB, 50 hash functions
protected void setup(Mapper<NullWritable, Any, IntWritable, Any>.Context context) {
Configuration conf = context.getConfiguration();
Path path = new Path(conf.get("conf.url.path"));
SequenceFile.Reader reader = new SequenceFile.Reader(conf, SequenceFile.Reader.file(path));
NullWritable key = NullWritable.get();
Any value = new Any();
while (reader.next(key, value)) {
urls.add(value.url.getBytes());
}
reader.close();
}
protected void map(NullWritable key, Any value,
Mapper<NullWritable, Any, IntWritable, Any>.Context context) {
if (value.session != null) {
/* Almost all irrelevant sessions are filtered out with this check,
* but small number of false positives still pass this filter. */
if (urls.contains(value.session.url.getBytes())) {
context.write(new IntWritable(value.session.url.hashCode()), new Any(value.session));
}
}
if (value.url != null) {
context.write(new IntWritable(value.url.hashCode()), new Any(value.url));
}
}
protected void reduce(IntWritable key, Iterable<Any> values,
Reducer<IntWritable, Any, NullWritable, Any>.Context context) {
Set<String> urls = new HashSet<>();
List<Session> sessions = new ArrayList<>();
for (Any value : values) {
if (value.url != null) {
urls.add(value.url);
}
if (value.session != null) {
sessions.add(value.session);
}
}
for (Session session : sessions) {
if (urls.contains(session.url)) {
context.write(NullWritable.get(), new Any(session));
}
}
}
...
/* Add URLs file as input and additionally pass path to it to mappers */
SequenceFileInputFormat.addInputPath(job, new Path("/sessions"));
SequenceFileInputFormat.addInputPath(job, new Path("/urls"));
job.getConfiguration().set(CONF_URL_PATH, "/urls");
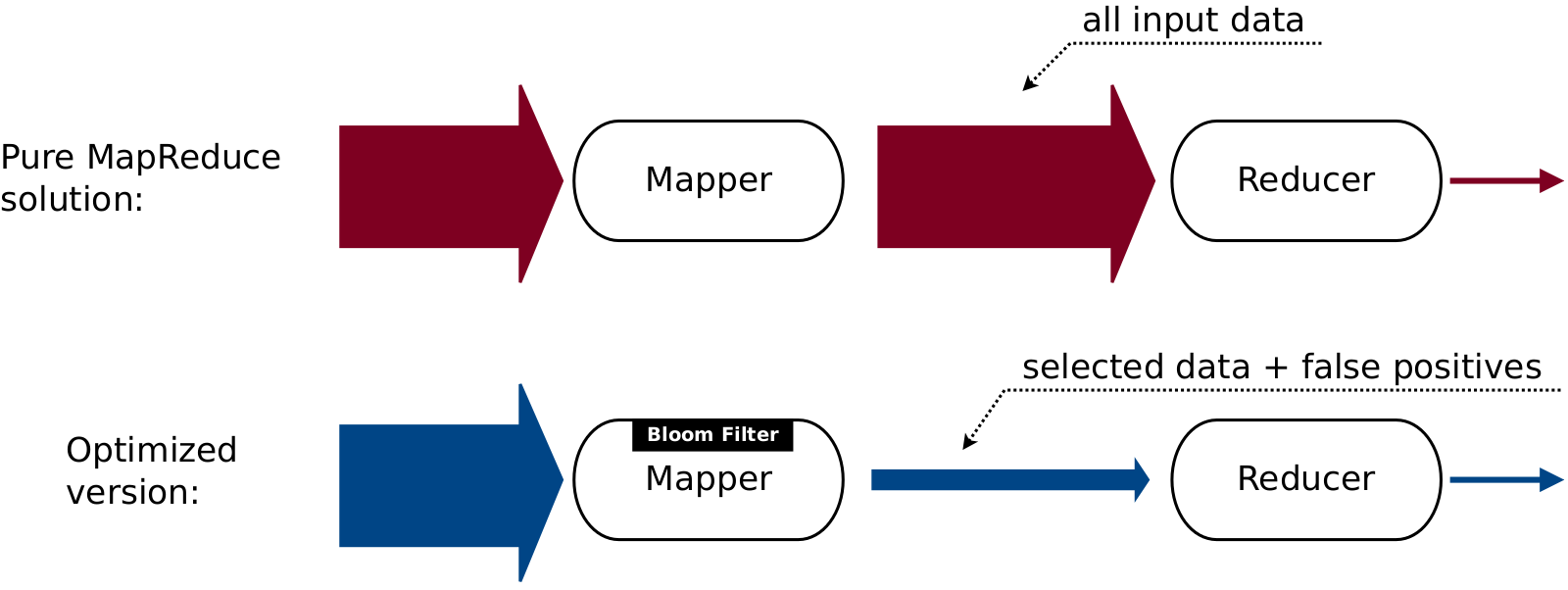
Above solution has all the properties we need. It scales well for any number of input URLs and session objects. It is efficient in terms of transferred data and, in turn, in terms of running time. It is easily tunable: we can set Bloom filter size to any value we like. It will affect performance through number of false positives emitted from mappers but not the correctness of the algorithm. Selecting optimal number of Bloom filter’s hash functions is a bit trickier as it involves counting number of URLs in advance, but in practice it can be avoided be choosing some fixed value (e.g. 50) at the cost of slightly worse than optimal number of false positives.
As in previous article, some optimizations were omitted for the sake of clarity.
If this code was intended for production use, then I would create Bloom filter in main() before
the job starts and pass it to mappers in serialized form to speed them up.
It is easy to do so, because Bloom filter is essentially just an ordinary bit array with a couple of parameters.
Add counters and tests, and you’ll get a production-grade solution for the frequently recurring SELECT problem.
Different problems may require some adaptations of the above approach. In particular, you should wisely choose data structure to filter data depending on its nature and volume:
-
use sorted array if key set fits into RAM
-
use sorted array of
hash(key)for larger key sets, but be aware that it produces false positives -
use bloom filter for even larger key sets
-
use prefix trees (trie) for string keys that have long common substrings, such as inverted URLs (
com.example.shop/apparel/women/dresses/https://) and semantic keys (SWAP-AUD-JPY-20170218)
But the idea is always the same: you want to filter out as much irrelevant data on mappers as you can. The less irrelevant data "leaks" to reducers, the more efficient overall job is.
Sources
Full source code can be found at github.