Books about Hadoop are usually focused on solving artificial problems. Learning from them creates false feeling of the simplicity of commercial coding with MapReduce. When time to solve real-world problems comes, it turns out that straightforward solution either doesn’t fit in resource limits (typically RAM) or runs for unacceptably long time. It takes months of practicing by trial and error before programmers accumulate enough experience to be able to create satisfactory solutions for real-world problems. In this article, I’ll describe example of recurring problem of exactly such kind — join of one to many relation. A series of issues will be identified and resolved, eventually leading to commercial-grade solution.
Our problem deals with joining two tables, one of which is thousands times larger than another one. Such problem is typical for MapReduce. For example, consider following practical problem. We are building advertising engine and we are interested in data analysis of user activity. Our primary table consists of immense amount of sessions. One session is a sequence of events related to a single user during short period of time, such as when some URL was loaded, page was scrolled down, advertisement was displayed or clicked. Such sessions are the basis for data analysis and user segmentation. Total size of sessions table may be extremely huge — dozens of terabytes stored in sequence files. Sessions are different in size: some users open website and leave soon, others do moderate amount of clicking, and finally, there are bad bots who automatically generate hundreds of clicks per each session.
In order to perform session classification and analysis, we would like to join sessions with information
about users, such as gender, age group and set of interests.
This information comes from various external data providers and can be joined with sessions by means of uid identifier,
which typically is some sort of tracking cookie.
Users table is much smaller than sessions table: relation between them is one-to-many, so that single user
may generate from zero to as many as thousands of sessions.
In the end, we would like to get a copy of sessions table where each session is enriched with information
about corresponding user.
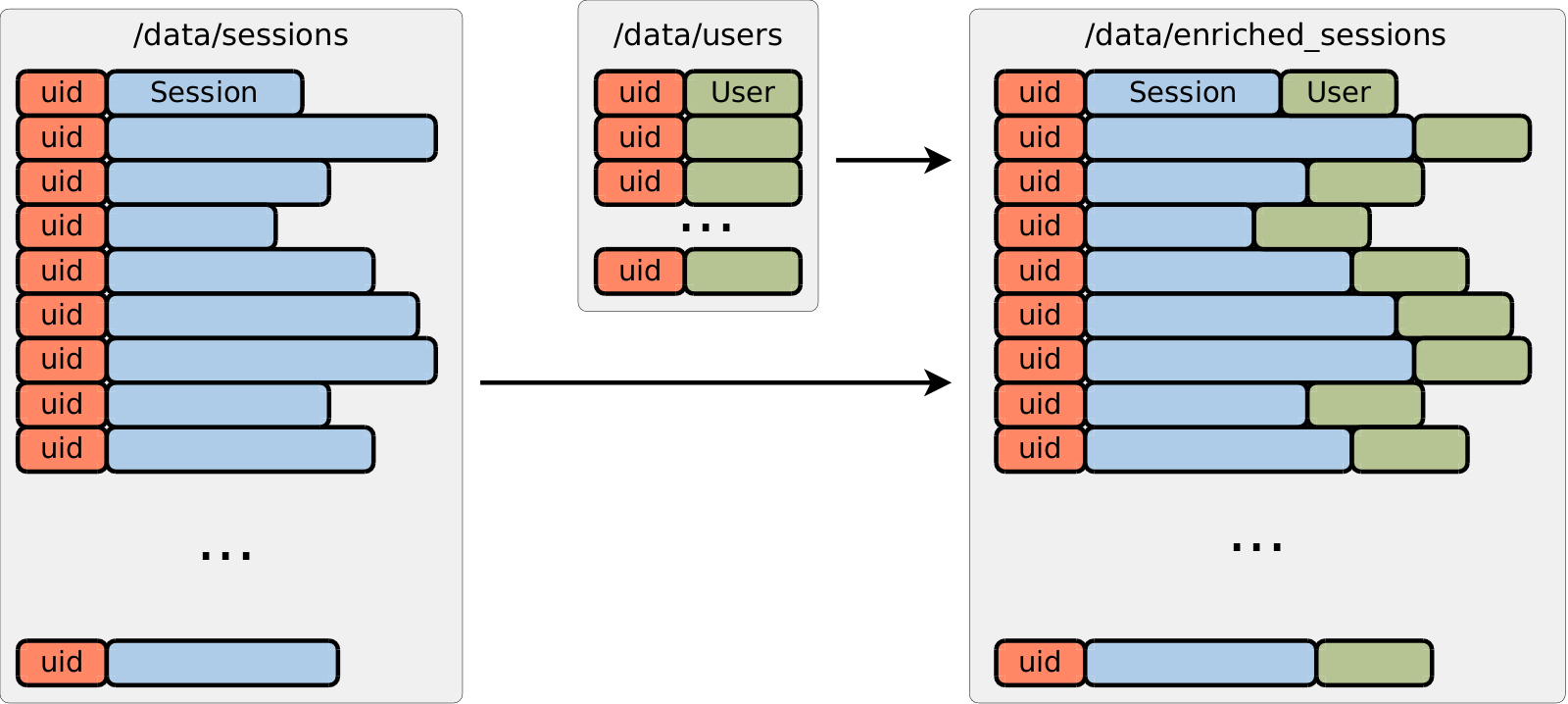
If you completed any random tutorial on Hadoop, then you should immediately come to the naive solution.
Let us create M/R job that accepts both data sources on input simultaneously.
Mapper doesn’t need to do anything special except emitting records <uid, Session> or <uid, User>
depending on the type of the input value.
It is the reducer that does actual join job.
It buffers all data about single user: user object goes into user variable,
and all sessions go into sessions array.
When input ends, reducer emits all buffered sessions enriching them with the same user.

In the code below, I create and use domain-specific container class Any which can hold
single user, single session or both.
Instances of Any are used to store all types of data: input files with sessions contain Any{session},
input file with users contain Any{user}, and output files with enriched sessions will contain both fields:
Any{session, user}.
This is a common trick that makes moving objects of different classes from mappers to reducers and from
one job to another one easy.
Otherwise, you’d have to create small separate container class for every job and setup Job appropriately.
Code below uses handmade Any class that implements Writable interface.
Multi-job task would require significantly more fields in Any class than just user and session
to cover the needs of the task at hand.
As such, for real-world problems I recommend to codegenerate Any by using protobuf or similar tool to avoid
tedious and error-prone job of implementing Writable methods by hand.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34 public class Any implements Writable {
public Session session;
public User user;
//...
}
protected void map(NullWritable key, Any value,
Mapper<NullWritable, Any, LongWritable, Any>.Context context) {
if (value.session != null) { // comes from sessions file(s)
context.write(new LongWritable(value.session.uid), new Any(value.session));
}
if (value.user != null) { // comes from users file(s)
context.write(new LongWritable(value.user.uid), new Any(value.user));
}
}
protected void reduce(LongWritable key, Iterable<Any> values,
Reducer<LongWritable, Any, NullWritable, Any>.Context context) {
List<Session> sessions = new ArrayList<Session>();
User user = null;
for (Any value : values) {
if (value.session != null) {
sessions.add(new Session(value.session));
}
if (value.user != null) {
if (user == null) { // ignore duplicate user objects
user = new User(value.user);
}
}
}
for (Session session : sessions) {
context.write(NullWritable.get(), new Any(session, user));
}
}
Alas, above code is doomed to fail. It assumes that all sessions of a single user fit into the RAM of one reducer process. While it is true for the vast majority of users, there will be definitely users with thousands of sessions, either real people or bots. The result is out of memory error in some of the reducers:
2017-02-12 21:48:58,395 FATAL [main] org.apache.hadoop.mapred.YarnChild: Error running child : java.lang.OutOfMemoryError: Java heap space
at mrhints.Session.readFields(Session.java:31)
at mrhints.Any.readField(Any.java:52)
at mrhints.Any.readFields(Any.java:37)
at org.apache.hadoop.io.serializer.WritableSerialization$WritableDeserializer.deserialize(WritableSerialization.java:71)
...
2017-02-12 21:48:58,842 INFO [main] mapreduce.Job (Job.java:printTaskEvents(1453)) - Task Id : attempt_1486921044666_0003_r_000000_0, Status : FAILED
Error: Java heap space
What can we do?
Fast and dirty solution is to limit the number of buffered sessions at the cost of losing some data.
Once reduce() accumulates max allowed number of sessions per single uid, all further sessions are simply skipped.
Of course, we would like to avoid that: data is a precious resource for analysis to simply through it away.
We need some better solution.
Brief observation of the above piece of code reveals the source of the problem:
user object may appear in any position in the values stream.
This is the only reason why we have to buffer all sessions in RAM,
even though we do not perform any pairwise operations on them.
It would be great if we could somehow force user object to appear as the very first object in the values stream.
In this case, it won’t be necessary to buffer all sessions.
Instead, we would be able to enrich them and stream directly from the input to the output one by one.
Luckily M/R provides low level API specifically designed for such sort of problems.
But to use it, we need to understand how data is processed between mappers and reducers.
When some key/value pair is emitted from mapper, it immediately goes to partitioner,
which is responsible for deciding which reducer will get this key/value pair.
Default partitioner implementation scatters key/value pairs between reducers based on key.hashCode() % job.getNumReduceTasks(),
thus ensuring that pairs with identical keys will be delivered to the same reducer and that keys (but not key/value pairs)
will be uniformly distributed between reducers.
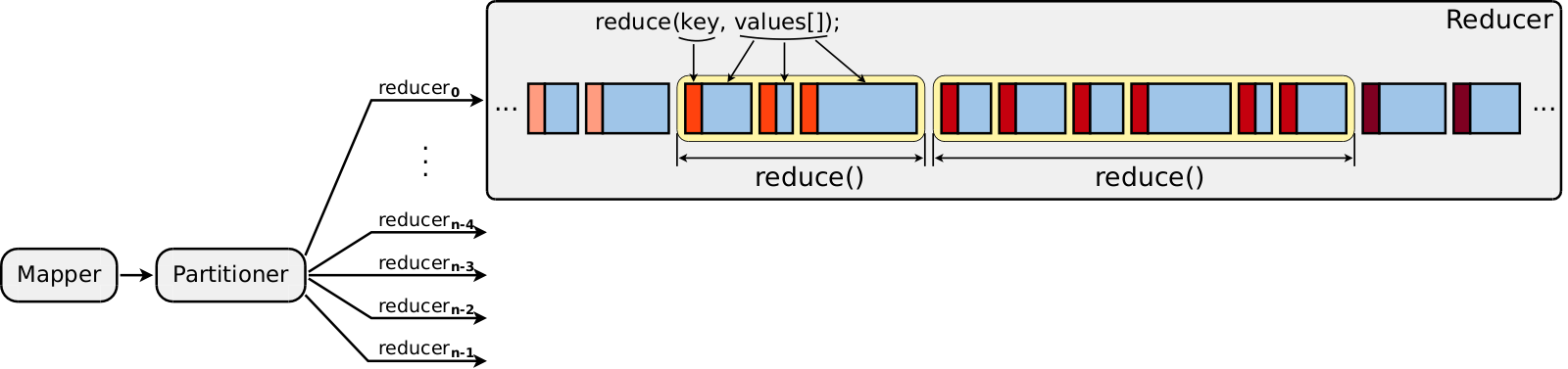
Reducer’s job is more complicated, it consists of three distinct phases.
During the first phase, reducer copies key/value pairs emitted by map() functions from all mappers.
In web interface, this phase is called reduce > copy and it occupies progress range between 0% and 33%.
Next phase is dedicated entirely to sorting of copied data into large sequential stream (reduce > sort, 33%..66%).
Key/value pairs become ordered in this stream according to sort comparator.
Similar to partitioner, its default implementation compares whole keys:
key/value pairs with identical keys are located adjacently in this stream,
but their pairwise order is unspecified.
For example, it may produce following sequence of key/value pairs: (k1, 15), (k1, 9), (k1, 10), (k1, 4).
Finally, reducer transitions to reduce > reduce phase (66%..100%) where actual reducing is done.
It scans sorted stream from the beginning and uses grouping comparator to
extract subsequences of key/value pairs which should be processed in single reduce() call.
If grouping comparator says that next key is identical to the previous one,
then its value is passed to the current reduce() call.
If grouping comparator says that next key is different,
then reducer completes current reduce() call (values.hasNext() returns false) and starts new one.
Hadoop’s ability to use different sort and grouping comparators makes it possible to sort not only keys,
but also values (implicitly) — exactly what we need.
| Name | API method | Responsibility |
|---|---|---|
Partitioner |
|
Chooses which of reducers gets key/value pair |
Sort comparator |
|
Orders key/value pairs in the input stream of a single reducer |
Grouping comparator |
|
Chops sequences of key/value pairs in an input stream of a single reducer, each such sequence is triggers separate |
Actual implementation of the above logic involves a number of optimizations. It is noteworthy that sort comparator works on both mappers and reducers. Mappers sort output directly on the fly. Reducers benefit from this because now all they need to do is to run merge sort on a number of already sorted streams from mappers, which is significantly cheaper than sorting everything from scratch. As such, do not get frustrated if your erronous implementation of sort comparator triggers mapper failure.
Let’s return back to our problem.
What we need to do is to create composite key JoinKey consisting of two fields:
first one is already mentioned uid, and second one is the flag identifying what is stored in value,
user (0) or session (1).
Such composite key makes it possible to order key/value pairs in a reducer stream in such way
that for each uid, its user object appears first (if exists), followed by a sequence of sessions.
Partitioner and grouping comparator must be manually implemented.
We want them to work as before, by comparing only uid field and ignoring value type field.
This ensures that all objects with the same uid are routed to the same reducer and to the same reduce() call.
Sorting comparator, on the other hand, compares both fields.
First it compares uid fields, and if they turn out to be equal, it further compares value type fields,
with user object considered to be “less” than session object.

Now reducer knows that user object (if present) always is the very first object in values stream.
This allows us to reimplement reducer to use only O(1) memory no matter how large reducer input is.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60 public static class JoinKey implements Writable {
public long uid;
public ValueType vtype;
//...
}
protected void map(NullWritable key, Any value,
Mapper<NullWritable, Any, JoinKey, Any>.Context context) {
if (value.session != null) {
context.write(new JoinKey(value.session.uid, ValueType.SESSION), new Any(value.session));
}
if (value.user != null) {
context.write(new JoinKey(value.user.uid, ValueType.USER), new Any(value.user));
}
}
public static class PartitionerImpl extends Partitioner<JoinKey, Any> {
public int getPartition(JoinKey key, Any any, int numPartitions) {
return ((int)(key.uid & 0x7fff_ffff)) % numPartitions;
}
}
public static class SortComparatorImpl implements RawComparator<JoinKey> {
public int compare(byte[] buf1, int off1, int len1,
byte[] buf2, int off2, int len2) {
JoinKey key1 = Utils.readObject(new JoinKey(), buf1, off1, len1);
JoinKey key2 = Utils.readObject(new JoinKey(), buf2, off2, len2);
return Utils.compareMultilevel(
Utils.compareLongs(key1.uid, key2.uid),
Utils.compareInts(key1.vtype.ordinal(), key2.vtype.ordinal())
);
}
}
public static class GroupingComparatorImpl implements RawComparator<JoinKey> {
public int compare(byte[] buf1, int off1, int len1,
byte[] buf2, int off2, int len2) {
JoinKey key1 = Utils.readObject(new JoinKey(), buf1, off1, len1);
JoinKey key2 = Utils.readObject(new JoinKey(), buf2, off2, len2);
return Utils.compareLongs(key1.uid, key2.uid);
}
}
protected void reduce(JoinKey key, Iterable<Any> values,
Reducer<JoinKey, Any, NullWritable, Any>.Context context) {
User user = null;
for (Any value : values) {
if (value.user != null) { // the very first record should be *user*
if (user == null) {
user = new User(value.user);
}
}
if (value.session != null) { // all further records should be *sessions*
if (user != null) {
context.write(NullWritable.get(), new Any(value.session, user));
}
}
}
}
Although it works as expected and doesn’t fail with out of memory error anymore,
there is still one severe problem left.
Number of sessions for some uid may be so huge, that reducer that joins its objects
runs tens or hundreds times longer than other reducers.
When this happens, you can see that all reducers but one complete in a matter of minutes,
while this poor guy is projected to last for one full day more.
This is unacceptable considering that join job is only a single step in multistage dataflow.
Add to that that if MapReduce cluster goes down, then this job has to be restarted from the very beginning.
The most pessimistic scenario consists of never-ending loop: start the job, wait until cluster failure,
curse Hadoop, repeat.
In general, long-lasting jobs is the primary coding problem with M/R.
It makes any ETA forecasting absolutely unreliable.
Deprived of any sense of confidence, programmers prefer to avoid batch processing in general and Hadoop in particular.

To solve the problem of non-uniform reducers, we will extend join key again.
Idea is to split sessions of a single uid into multiple reduce() calls,
like if they belonged to different users.
This is fine because we need only to join user object with every single session,
but we do not have any operations that require two sessions to be present in a single place simultaneously.
So, we are going to add third field to our JoinKey — shard number.
We select number of shards SHARDS from range [5 .. 100],
so that running time of heaviest reducer divided by SHARDS becomes acceptable.
The larger SHARDS value, the more uniform reducer load becomes.
But too large value would generate large amount of excessive data to sort and transfer between mappers and reducers.
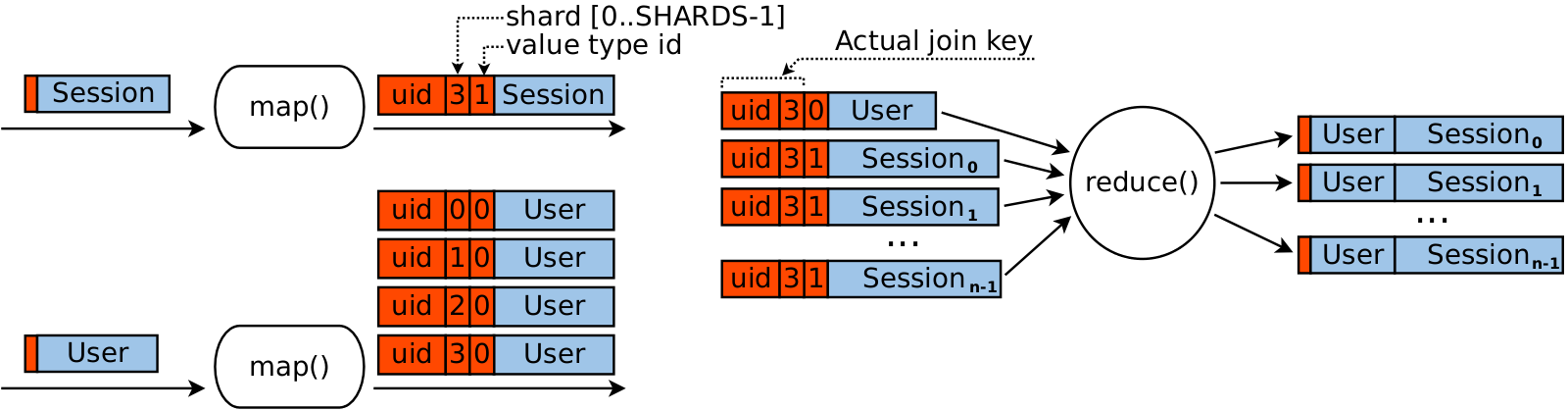
Now we think of a pair {uid, shard} as of true join key, while full triplet — {{uid, shard}, vtype} — is used only for sorting as in previous version.
When mapper encounters session object, its shard is computed as session.hashCode()%SHARDS, thus ensuring
that sessions of a single uid will be scattered almost uniformly between reducers rather than delivered to
a single reducer.
When mapper encounters user object, it emits SHARDS identical values but with different keys:
their shard value runs from 0 to SHARDS-1.
Implementation of reducer is not changed from previous version.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53 public static class JoinKey implements Writable {
public long uid;
public ValueType vtype;
public int shard;
...
}
protected void map(NullWritable key, Any value,
Mapper<NullWritable, Any, JoinKey, Any>.Context context) {
if (value.session != null) {
int shard = (Arrays.hashCode(value.session.data) & 0x7fff_ffff) % SHARDS; // [0..SHARDS-1]
context.write(new JoinKey(value.session.uid, ValueType.SESSION, shard), new Any(value.session));
}
if (value.user != null) {
for (int shard = 0; shard < SHARDS; shard++) {
context.write(new JoinKey(value.user.uid, ValueType.USER, shard), new Any(value.user));
}
}
}
public static class PartitionerImpl extends Partitioner<JoinKey, Any> {
public int getPartition(JoinKey key, Any any, int numPartitions) {
int hash = 1;
hash = hash * 13 + (int)(key.uid & 0xffff_ffff);
hash = hash * 13 + key.shard;
return (hash & 0x7fff_ffff) % numPartitions;
}
}
public static class SortComparatorImpl implements RawComparator<JoinKey> {
public int compare(byte[] buf1, int off1, int len1,
byte[] buf2, int off2, int len2) {
JoinKey key1 = Utils.readObject(new JoinKey(), buf1, off1, len1);
JoinKey key2 = Utils.readObject(new JoinKey(), buf2, off2, len2);
return Utils.compareMultilevel(
Utils.compareLongs(key1.uid, key2.uid),
Utils.compareInts(key1.shard, key2.shard),
Utils.compareInts(key1.vtype.ordinal(), key2.vtype.ordinal())
);
}
}
public static class GroupingComparatorImpl implements RawComparator<JoinKey> {
public int compare(byte[] buf1, int off1, int len1,
byte[] buf2, int off2, int len2) {
JoinKey key1 = Utils.readObject(new JoinKey(), buf1, off1, len1);
JoinKey key2 = Utils.readObject(new JoinKey(), buf2, off2, len2);
return Utils.compareMultilevel(
Utils.compareLongs(key1.uid, key2.uid),
Utils.compareInts(key1.shard, key2.shard)
);
}
}
Above piece of code completes the solution of the join problem. It works for any input data volume and takes acceptable amount of time to complete. Experienced programmer would further add number of improvements which I omitted for the sake of clarity: avoid deserialization in comparators, increase object reuse, add counters and asserts. Anyway, above solution should give you the feeling that coding with MapReduce is not so easy as described in tutorials. In general, simplicity of the MapReduce concept is a benefit and a drawback at the same time. On the one hand, its basics can be learned very fast. On the other hand, even basic problems require constructing complicated dataflow because of overly simplistic MapReduce model.
Sources
Full source code can be found at github.