MinHash is a technique widely used to compare texts for similarity. For example, in web search it is used to detect mirror sites. Mirror is a site that clones the contents of another site either verbatim or very closely. Web search engines are interested in mirror detection because of two reasons. First of all, it significantly reduces cost of maintaining search engine. Search engines typically index contents of only the primary web site (highestly ranked) and ignore all its mirrors. Secondly, mirrors to well-known sites often indicate phishing, which raises red flags for security team. Another application of MinHash is plagiarism detection. Universities and scientific magazines are interested to automatically recognize copypasted papers and thesises.
MinHash algorithm has a number of variations. In this article I will focus on the MinHash variation that uses single hash function. Such type of MinHash is computationally fast to construct, but computation of similarity score between a pair of documents using their MinHashes is slow. This limits application of this variation of MinHash to the collections of documents of small to moderate sizes.
The high-level workflow is the following: for every text you have, split it into sequence of words, then create a set of every K-tuple of adjacent words (I will use K=3 below; every such triplet is called a shingle), then hash these shingles into 32-bit hashes, and finally select smallest unique N shingles. These N shingles become the fingerprint (MinHash) of the text. N is chosen typically from about 50 to a couple of hundreds depending on the median size of the text of the collection.
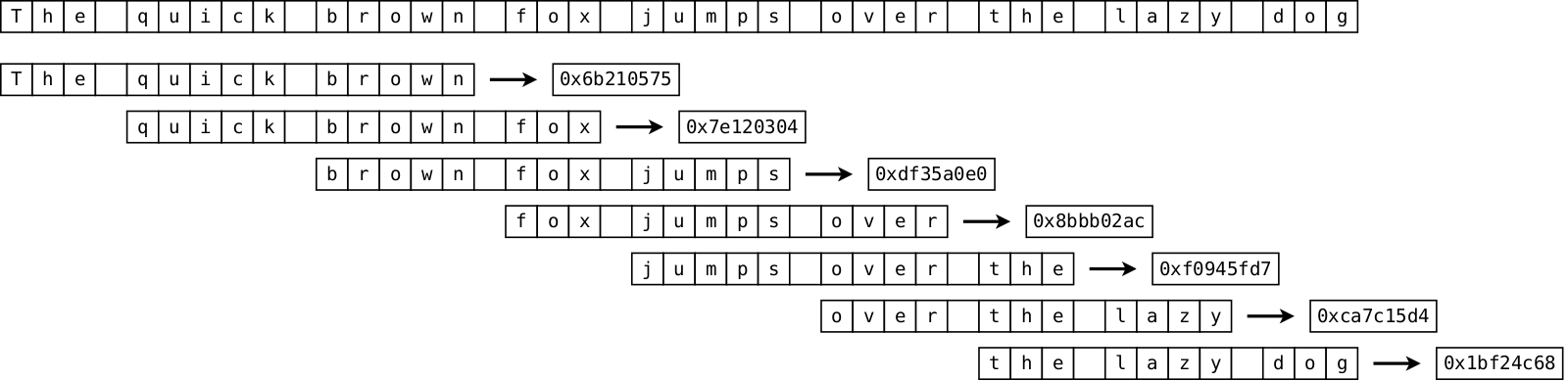
Once fingerprints are generated for every text, we can compute similarity of any pair of texts by computing their Jaccard score of their fingerprints:
It can be proved that there is correlation between closeness of two texts and their similarity score  .
For any pair of documents, the closer Jaccard score between their fingerprints to one,
the closer Jaccard score between their full sets of shingles to one,
and the closer the texts themselves are.
For example, we can set threshold value to 0.8.
If Jaccard score exceeds 0.8, then we conclude that two texts are nearly identical.
.
For any pair of documents, the closer Jaccard score between their fingerprints to one,
the closer Jaccard score between their full sets of shingles to one,
and the closer the texts themselves are.
For example, we can set threshold value to 0.8.
If Jaccard score exceeds 0.8, then we conclude that two texts are nearly identical.
The good thing about MinHash is that it is robust to minor modifications to the text. For example, web pages often contain some elements which become different when site is mirrored, such as current timestamp, domain name or manually added disclaimers. Just comparing texts character-by-character would not be enough. Another good thing about MinHash is that no matter how large input texts are, the fingperprints it computes are of fixed, short lengths. Fingerprint consisting of 128 32-bit hashes is only 512 bytes.
However, even this "computationally cheap" variant is expensive in practice.
In this article I will demonstrate efficient implementation of fingerprint generation and pair-wise
computation of  .
.
First task is tokenizing text into words. Usually high-quality text analysis requires NLP-based models. For example, it is desirable to treat "N.B.A." identically to "NBA" rather than consisting of three distinct tokens "N", "B", "A". Similarily, words "happy" and "happiness" are usually stemmed to the same root "happi". Luckily, in similarity detection we don’t need this level of complexity due to probabilistic nature of the algorithm, and can define a word simply as a sequence of adjacent alphanumeric characters. Remaining (non-alphanumeric) characters are the delimeters.
Assuming that text is a sequence of 16-bit unicode code points, the number of alphanumeric characters is large and, worse, they do not form adjacent region. In the image below, there is one pixel per every 16-bit code point. Red pixels denote alphanumeric code points.

The only reasonable way to store this information is in a lookup table with one bit
per every code point.
The table below was prebuilt in Java by probing code points with Character.isLetterOrDigit(char c).
__attribute__((aligned(64))) const uint64_t kAlphanumTable[] = {
0x03ff000000000000, 0x07fffffe07fffffe, 0x0420040000000000, 0xff7fffffff7fffff,
0xffffffffffffffff, 0xffffffffffffffff, 0xffffffffffffffff, 0xffffffffffffffff,
0xffffffffffffffff, 0xffffffffffffffff, 0xffffffffffffffff, 0x0000501f0003ffc3,
/* ... */
0x3fffffffffffffff, 0xffffffffffff0000, 0xfffffffffffcffff, 0x0fff0000000000ff,
0x0000000000000000, 0xffdf000000000000, 0xffffffffffffffff, 0x1fffffffffffffff,
0x07fffffe03ff0000, 0xffffffc007fffffe, 0x7fffffffffffffff, 0x000000001cfcfcfc,
};
inline bool IsAlphanum(unsigned int c) {
return (kAlphanumTable[c/64] >> (c%64)) & 0x1;
}Before we continue forward, let’s choose hash function.
We want it to be relatively fast to compute but complex enough to be robust to permutations,
e.g. we want for "word1 word2 word3" and "word1 word3 word2" to be hashed to different values.
Thus, per-character XOR is a bad idea.
Taking into consideration the above requirements, I chose
FNV-1a.
It is well studied, widely used in practice (glibc implements std::hash<T> by using it),
not very expensive (two multiplications per 16-bit character), and also easy to code.
uint32_t fnv1a(const uint16_t* str, int len) {
uint32_t hash = 2166136261;
for (size_t i = 0; i < len; i++) {
uint16_t c = str[i];
hash = hash ^ (c & 0xff);
hash = hash * 16777619;
hash = hash ^ (c >> 16);
hash = hash * 16777619;
}
return hash;
}First place where we can get significant gains in performance is shingle generation algorithm. Below pseudocode demonstrates naive implementation. It is implemented exactly as visualized in the very first image. First, we split text into an array of separate words. Next we are iterating over every sequence of K=3 adjacent words, compute and emit hash.
words[] = Tokenize(text)
for i := 0 .. words.length()-3:
hash = InitHash()
for k := 0 .. 2:
for j := 0 .. words[i+k].length
hash = UpdateHash(hash, words[i+k][j])
Collect(hash)Noticeable issue is that a copy of input text is made into the words array. It shouldn’t be very hard to avoid copying because shingling is a type of streaming algorithm, i.e. we need only to keep track of a sliding window of K=3 consecutive words at a time.
But we can do even better by implementing pipeline. To do this, we are going to store K=3 partially computed hashes. All these hashes are updated every time we read new alphanumeric character. When the word is over, the head of the pipline is the full hash of the previous K words, next element after the head is the partial hash for the last K-1 words, and so on. When the word is over, we eject the head of the pipeline and shift the remaining hashes.
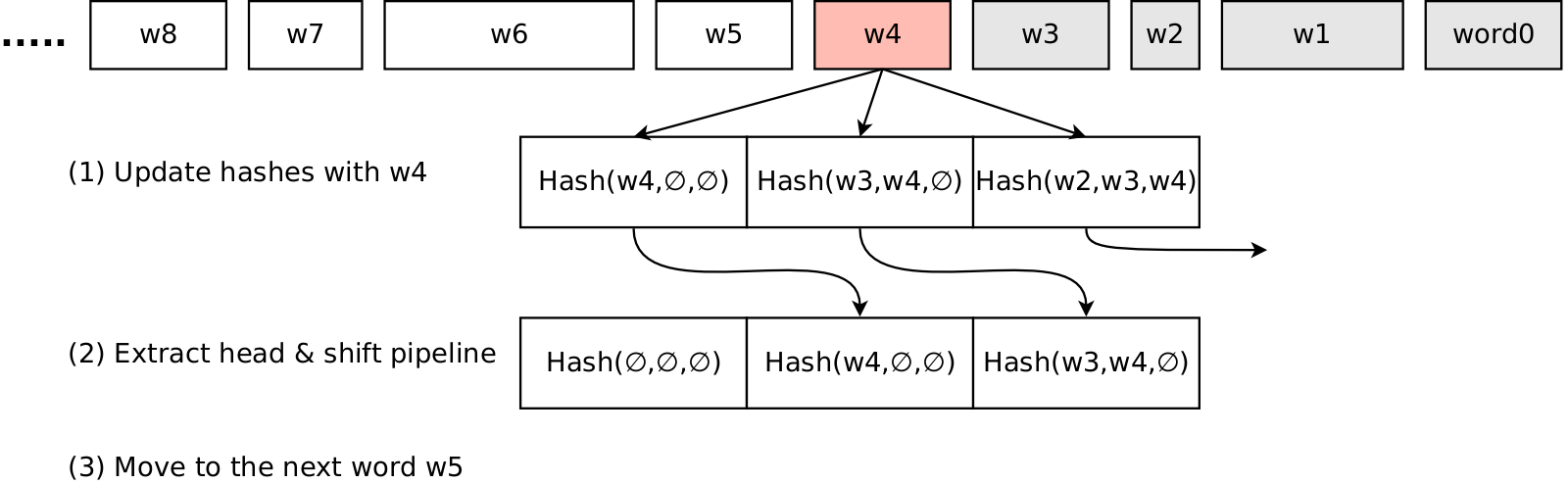
template<int K> // shingle length in words, e.g. K=3
const uint16_t* txt; // arg
int txt_length; // arg
...
// main loop
size_t i = 0;
uint32_t pipeline[K];
while (i < txt_length) {
// process next word
while (i < txt_length && IsAlphanum(txt[i])) {
uint16_t c = txt[i];
for (int k = 0; k < K; k++) {
pipeline[k] = pipeline[k] ^ (c & 0xff);
pipeline[k] = pipeline[k] * 16777619;
pipiline[k] = pipeline[k] ^ (c >> 16);
pipeline[k] = pipeline[k] * 16777619;
}
i++;
}
// collect head of the pipeline
Collect(pipeline[0]);
// shift pipeline
for (int k = 0; k < K-1; k++) {
pipeline[k] = pipeline[k+1];
}
pipeline[K-1] = 2166136261;
// skip delimiter
while (i < txt_length && !IsAlphanum(txt[i])) {
i++;
}
}It is important that K is known at compile time and is not a runtime argument. Because K is small (K=3 in our case), compiler unrolls the loop:
xorl %edx, %eax
xorl %edx, %r13d
xorl %r12d, %edx
imull $637696617, %eax, %eax
imull $637696617, %r13d, %r13d
imull $637696617, %edx, %r12dUnrolling has obvious benefit of avoiding conditional check at every iteration. But more important is that because iterations are independent from one another, CPU can execute instructions in parallel. This leads to significant speedup.
The most simple way would be to collect all hashes into a vector, sort them and then return smallest N hashes.
Experienced algorithmist may know a way to do this without sorting all hashes, by using std::partial_sort.
Its idea is similar to quick sort: at every step we choose pivot and exchange
elements so that in the end array consists of two groups of elements:
elements which are less or equal to pivot go to the beginning, while elements larger than pivot
go to the end of the array.
We repeat the process multiple times always by using left group.
Right group is of no importance and is ignored.
But std::partial_sort still implies that we need to collect all hashes somewhere.
This may be unfeasable for large texts.
We would like to design streaming algorithm with O(N) space.
This leads to the idea of storing N smallest hash values in sorted array.
As such, we can check the presense of an element in O(log N).
Inserting is more expensive because it requires to shift N/2 elements on average.
Even better idea is to use heap.
It would make insert really fast.
But the trouble is that our values are not unique,
and checking for element existance in a heap is O(N) time.
To avoid such expensive check, in addition to heap we can maintain
a hash table that would guard heap from receiving duplicate elements.
So, now the algorithm becomes like this: for every incoming hash,
check that it is smaller than heap.peek(),
check that it is not present in the hash table,
and if both conditions are satisfied, then update both heap and hash table by removing
heap.peek() element and inserting the incoming hash.
This version is asymptocitally optimal, but it still has some problems related to the nature of hash table. Classical hash table uses dynamical memory allocations, linked lists and it also hashes values, even though our elements are already high quality hashes themselves. What if we could replace classical hash table with a simpler one? We know the number of elements we are going to store in it in advance and also we have copy of all elements in a heap, so we have something to offer in return. After some time spent on thinking and benchmarking, this leads to the following solution. Classical hash table is replaced with manually created hash table with the following properties:
-
It is just an array of 4N uint32_t slots. No more than 2N elements are going to be stored at any given time to ensure search/insert in O(1) time.
-
Special uint32_t value denotes empty slot.
-
Elements are inserted by using linear probing: if the desired slot is occupied, we scan table below until we find free slot. This is safe because no more than 2N elements will ever be stored there.
The tradeoff is that such implementation doesn’t allow deletions. But this is not a problem. As soon as table becomes 2N full, we just remove all elements from the table and repopulate it from the heap. As such, load factor of the table oscillates betwen 0.25 and 0.5.
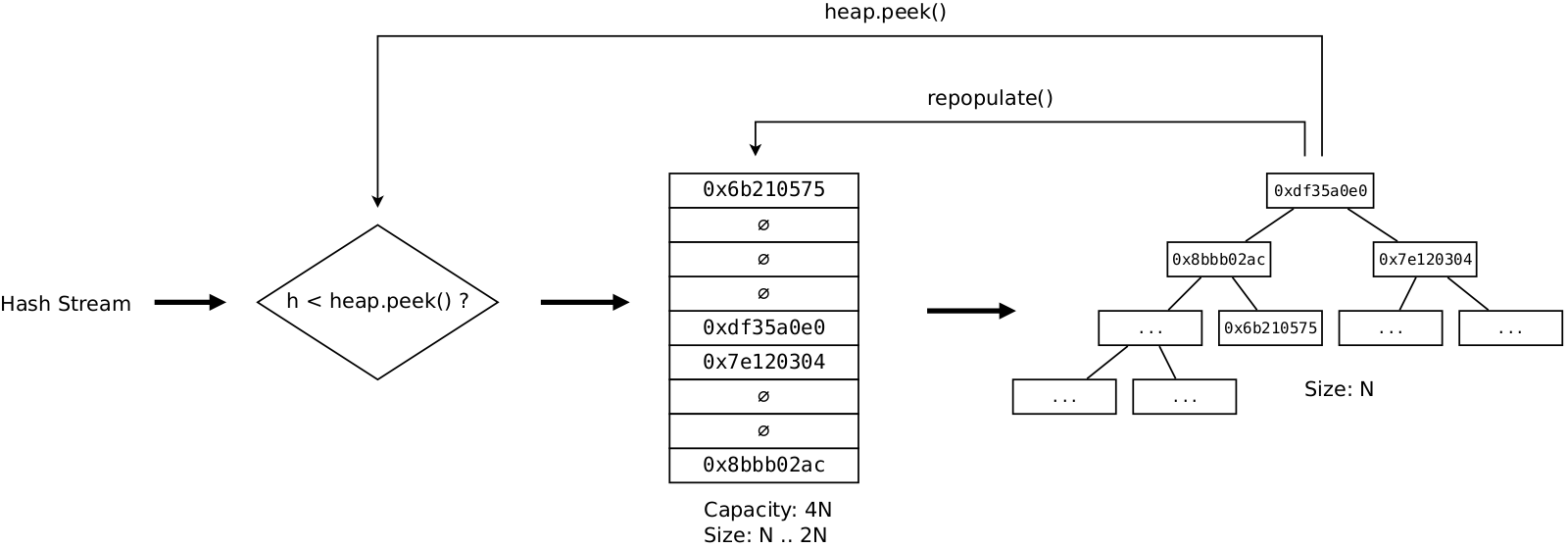
Below is the pseudo-code for the main loop:
def Collect(h):
if h < heap[0]:
if !htable.contains(h):
htable.insert(h)
heap.pop(heap)
heap.push(heap, h)
if htable.size() >= N*2:
htable.clear()
for i := 0 .. heap.size()-1:
htable.insert(heap[i])In the result we have a solution with O(1) time to check whether an element exists, and with O(log N) insertion time. Occasionally hash table must be repopulated, but this happens rarely and thus its contribution to the total time is negligible.
Test collection consists of 1000 long articles from Wikipedia, varying in size from 16KB to 540KB.
| Time [s] | MChars/s | Speedup | |
|---|---|---|---|
naive |
0.939594 |
52.7 |
1.0 |
pipeline + sort |
0.513581 |
96.3 |
1.8 |
pipeline + unordered_set + heap |
0.276099 |
179.2 |
3.4 |
pipeline + custom htable + heap |
0.177911 |
278.1 |
5.3 |
First version is the naive, reference implementation of everything.
Second version uses pipelined shingle generation, but still collects and sorts all hashes to find N smallest.
Third version uses heap to find N smallest hashes, guarded by std::unordered_set<uint32_t>.
Final version is the modification where unordered set is replaced with custom hash table.
It reaches throughput of 278M characters per second — more than enough not to be a bottleneck
in a data pipeline.
At this point we have fingerprints for every document of the collection. A fingerprint is a sorted array of up to N 32-bit hashes. To compute Jaccard similarity score between two documents, we need to find the cardinality of their fingerprint intersection. This can be done with the classical algorithm:
double JaccardClassical(const uint32_t* fng1, int len1,
const uint32_t* fng2, int len2)
{
int pos1 = 0;
int pos2 = 0;
int nintersect = 0;
while (pos1 < len1 && pos2 < len2) {
if (fng1[pos1] == fng2[pos2]) {
nintersect++;
pos1++;
pos2++;
} else if (fng1[pos1] < fng2[pos2]) {
pos1++;
} else {
pos2++;
}
}
int nunion = len1 + len2 - nintersect;
return nintersect / (double) nunion;
}We wouldn’t trouble ourselves with optimization of this algorithm if it would be necessary to compute Jaccard score for only a pair of documents. The problem is that in practice it is usually required to solve one of the following more complex problems:
-
Given a collection of documents and a new document, find all documents in the collection which have Jaccard score with the given document ≥ threshold (e.g. plagiarism detection).
-
Given a collection of documents, find all pairs of documents with Jaccard score ≥ threshold (clusterization).
Both algorithms are very expensive due to large number of Jaccard similarity score computations. For example in case of clusterization, if we have 10K documents, it would be necessary to compute Jaccard score ~50M times. So, it is crucial to optimize the above algorithm.
We can make two observations.
First one is that we don’t care about Jaccard scores smaller than threshold.
If at some point during score computation we detect that cannot be greater or equal to the threshold,
we can immediately abort computation and return 0.0.
Only values higher than the threshold matter.
Let’s assume that we have already processed  and
and  hashes of the first and second
fingerprints respectively, and the number of identical hashes was
hashes of the first and second
fingerprints respectively, and the number of identical hashes was  .
Then is subject to the following boundaries:
.
Then is subject to the following boundaries:
Let’s assume that we are interested only in Jaccard score greater or equal to threshold  .
If at any step the following condition is satisfied, we can immediately abort computation,
since we know that final will be smaller than the desired threshold:
.
If at any step the following condition is satisfied, we can immediately abort computation,
since we know that final will be smaller than the desired threshold:
Simplifying:
Since we know that  , we can tighten the abort condition
to get rid of
, we can tighten the abort condition
to get rid of  function:
function:
Again, let’s tighten condition, now to avoid working with floating point:
Now let’s plug the above formula into the classical solution.
Right-hand side can be computed once we enter the function.
A new variable,  , stores the value of
, stores the value of  .
We update it each time we advance the positions.
If at some point it exceeds precomputed rind-hand side value, we abort the computation.
.
We update it each time we advance the positions.
If at some point it exceeds precomputed rind-hand side value, we abort the computation.
double JaccardFast(const uint32_t* fng1, int len1,
const uint32_t* fng2, int len2,
double alpha)
{
const int smax = (int)std::ceil((1.0-alpha)/(1.0 + alpha) * (len1 + len2));
int pos1 = 0;
int pos2 = 0;
int nintersect = 0;
int s = 0;
while (pos1 < len1 && pos2 < len2) {
if (fng1[pos1] == fng2[pos2]) {
nintersect++;
pos1++;
pos2++;
/* s = s + 1 + 1 - 2 = s */
} else if (fng1[pos1] < fng2[pos2]) {
pos1++;
s++;
} else {
pos2++;
s++;
}
if (s > smax) {
return 0.0;
}
}
int nunion = len1 + len2 - nintersect;
return nintersect / (double) nunion;
}The second significant observation is that in 99% of all cases Jaccard score is smaller than threshold.
Given a pair of fingperprints of two random documents, very few hashes will be identical among them.
To skip large blocks of nonintersecting hashes, we can make use of
pcmpesmtrm SSE intruction.
Its intended application is fast string operations, such as substring search.
However, other applications were found for this instruction, including
intersecting
of two sorted arrays.
Alas, pcmpesmtrm works natively only with 8- and 16-bit elements,
while shingle hashes are 32 bit long.
If they were 8 or 16 bits, we could just use the code from the article verbatim.
But because our elements are 32 bit long, we can use this instruction only as a prefilter:
we treat every 32-bit hash as a sequence of two 16 bit elements.
If the instruction returns non-zero mask (some of the 16-bit elements are equal),
this doesn’t prove that there are equal 32-bit elements.
But if returned mask is zero, then definitely none of the 32-bit elements are equal.
In this case we can advance one of the fingerprint positions by a block of four 32-bit hashes in bulk.
Taking into account that hashes do match very rarely, such precheck is worse the cost
paid for pcmpesmtrm.
double JaccardTurbo(const uint32_t* fng1, int len1,
const uint32_t* fng2, int len2,
double alpha)
{
int smin = (int)std::ceil((1.0-alpha)/(1.0 + alpha) * (len1 + len2));
int pos1 = 0;
int pos2 = 0;
int nintersect = 0;
int s = 0;
while (pos1+4 <= len1 && pos2+4 <= len2) {
__m128i v1 = _mm_loadu_si128((const __m128i*)(fng1 + pos1));
__m128i v2 = _mm_loadu_si128((const __m128i*)(fng2 + pos2));
uint64_t m = _mm_cvtsi128_si64(_mm_cmpestrm(v1, 8, v2, 8,
_SIDD_UWORD_OPS|_SIDD_CMP_EQUAL_ANY|_SIDD_BIT_MASK));
if (m) {
// we have possible matches -- using classical algorithm
for (int i = 0; i < 4; i++) {
if (fng1[pos1] == fng2[pos2]) {
nintersect++;
pos1++;
pos2++;
} else if (fng1[pos1] < fng2[pos2]) {
pos1++;
s++;
} else {
pos2++;
s++;
}
}
} else {
// no matches
if (fng1[pos1+3] < fng2[pos2+3]) {
pos1 += 4;
} else {
pos2 += 4;
}
s += 4;
}
if (s > smax) {
return 0.0;
}
}
// process up to three remaining hashes
while (pos1 < len1 && pos2 < len2) {
if (fng1[pos1] == fng2[pos2]) {
nintersect++;
pos1++;
pos2++;
} else if (fng1[pos1] < fng2[pos2]) {
pos1++;
} else {
pos2++;
}
}
int nunion = len1 + len2 - nintersect;
return nintersect / (double) nunion;
}The following table summarizes performance results of the above three versions. All documents in a collection of 2000 documents were compared pairwise, resulting in total of ~2M computations. Shingle parameters were N=128 and K=3, threshold value was set to 0.5.
| Time [s] | Computations/s | Speedup | |
|---|---|---|---|
classical |
2.372734 |
0.84 M/s |
1.00 |
classical + fast abort |
1.041861 |
1.92 M/s |
2.28 |
classical + pcmpestrm + fast abort |
0.632168 |
3.16 M/s |
3.75 |
Since documents in the collection were Wikipedia pages, you may be interested
to know which pages had the highest .
I found three main caterogries: pages listing rulers for some specific year;
pages listing animals of African countries;
and surprisingly similar user discussion pages (probably, created by bots).
To give some understanding of performance limitations, let’s assume that we need to clusterize large collection of documents and we are alotted a single CPU core for 24 hours. Using the optimized version will allow us to process a collection of ~740K documents. For larger collections it may be suitable to use MinHash version with multiple hash functions. I will describe it later in the next article.
C++ source code is located at github.